DevOps y Bases de Datos - Estrategia de Versionamiento
El primer gran reto que debemos enfrentar en esta guía es poder definir una estrategia de versionamiento para nuestras bases de datos, esta estrategia no debe confundirse con los ramales (branches) dentro del control de versiones. Para nosotros, el esquema de versionamiento es el mecanismo por el cual podemos identificar el estado, en un punto del tiempo, dentro de la evolución de nuestro modelo o esquema de datos. Esta entrega planteará una estrategia que permitirá administrar esta evolución del modelo de forma organizada.
Antes de entrar en detalles debo aclarar que no voy a buscar un proceso idempotente, las herramientas tradicionales simplemente no tienen las características necesarias y simplemente ignoran esta necesidad (la cláusula EXISTS se queda corta por mucho), por otro lado, las herramientas más visionarias en este ámbito (como es el caso de 2bass), aun cuando establecen un esquema órdenes de magnitud superior, personalmente creo que no han alcanzado un nivel de madurez suficiente que me haga sentir cómodo para recomendarlas. Debe comprenderse que si el proceso fuera idempotente, los scripts serían declarativos y definirían el estado final del modelo de datos sin preocuparnos por las transformaciones que tienen que ocurrir ni de cómo van a ocurrir (aunque esto significara truncar datos), en otras palabras, en un proceso idempotente mi script indicaría por ejemplo, cuáles son las columnas que debe tener la tabla y al aplicarlo el motor analizaría cuales columnas deben eliminarse, cuales agregarse y cuales modificarse para cumplir llegar al estado deseado, por supuesto la información almacenada en la tabla sufre cambios muchas veces irreversibles, esto es precisamente la complejidad que enfrentan las herramientas visionarias antes mencionadas. Por estos motivos mi implementación está basada a nivel de proceso.
Versión de una base de datos
Para poder definir nuestra estrategia de versionamiento debemos primero establecer que la “versión” en una base de datos obedece a dos elementos:
- La evolución del modelo o esquema de datos
- La evolución de los datos almacenados
Obviamente, la evolución de los datos está completamente fuera de nuestro control y obedece a la interacción de los usuarios y sistemas con la base de datos, la única forma de tener esquemas de “versiones” de bases de datos que contemplen los dos elementos es por medio de las funcionalidades de respaldos o copias de seguridad que los diferentes motores ofrecen. Por otro lado, la evolución del modelo está completamente bajo nuestro control y es posible administrarla para que esta ocurra de manera controlada.
Para poder llevar nuestra estrategia a la realidad trabajaremos bajo una premisa: Todo cambio al esquema se ejecutará directamente por medio de código fuente, esto es lo que se conoce como Schema as Code y al igual que Infrastructure as Code tiene como objetivo tener trazabilidad de todos los cambios en código fuente para poder repetir los ambientes de forma confiable. Deben entenderse las implicaciones… procedimientos almacenados, tablas, índices, llaves, etc., todo debe definirse y aplicarse por medio de código.
Mantener el esquema o modelo como código es un proceso relativamente sencillo, incluso podríamos usar las herramientas gráficas y en lugar de aplicar los cambios, generar los scripts y guardarlos como nuevas versiones en el sistema de control de código fuente, el problema con este formato es que no se cuenta con un mecanismo sencillo que nos permita confiar que los cambios en código que estamos aplicando a un servidor, cuentan con todo el soporte necesario de objetos y estructuras en la base de datos… Es decir, al agregar un nuevo objeto que depende de otros ya existentes debería tener un mecanismo que me indicara si los prerrequisitos están presentes antes de disparar mis cambios.
De una manera muy simplificada, lo anterior puede explicarse en el siguiente diagrama, al aplicar un cambio se verifica el estado de la base de datos y luego se aplica; deshacer un cambio requiere el proceso inverso, verificar el estado (validando que el cambio a revertir está presente) para luego realizar modificaciones que contrarresten cambios anteriores.
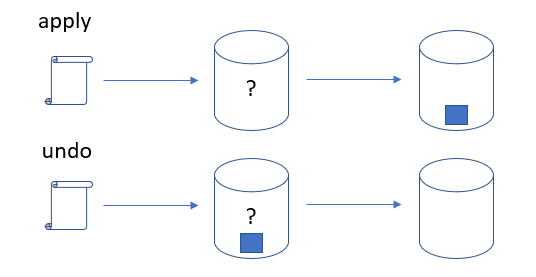
Si bien es posible hacer una revisión exhaustiva de la estructura de la base de datos para identificar la versión actual (lo cual nos acercaría a un proceso idempotente), yo voy a valerme de un artificio más simple. En esta estrategia la versión actual será mantenida como metadatos que identificarán de forma única el último cambio aplicado, el repositorio de estos metadatos puede ser elegido libremente, una opción obvia sería almacenarlo en una tabla dentro de la base de datos; sin embargo, como la implementación de ejemplo está basada en Microsoft SQL Server voy a utilizar una característica nativa para al almacenamiento de metadatos, las propiedades extendidas. La idea es utilizar un identificador único universal almacenado en una propiedad extendida que será actualizado (ya sea con una versión nueva o con una inmediata anterior) en cada cambio enviado a la base de datos.
Para implementar esta tarea no necesitamos más que unos pocos procedimientos almacenados que estratégicamente colocaremos dentro de un esquema llamado cicd
CREATE SCHEMA cicd
GO
CREATE PROCEDURE cicd.SetProperty
@n NVARCHAR(128),
@v NVARCHAR(128)
AS
DECLARE @current NVARCHAR(128)
SELECT @current = [name] FROM fn_listextendedproperty(@n, NULL, NULL, NULL, NULL, NULL, NULL)
IF(@current IS NULL)
EXEC sp_addextendedproperty @name = @n, @value = @v
ELSE
EXEC sp_updateextendedproperty @name = @n, @value = @v
GO
CREATE PROCEDURE cicd.GetProperty
@n NVARCHAR(128),
@v NVARCHAR(128) OUTPUT
AS
SELECT @v = CAST([value] AS VARCHAR(128)) FROM fn_listextendedproperty(@n, NULL, NULL, NULL, NULL, NULL, NULL)
IF(@v IS NULL)
RETURN 1
ELSE
RETURN 0
GO
CREATE PROCEDURE cicd.SetVersion
@id UNIQUEIDENTIFIER
AS
EXEC cicd.SetProperty 'CICD-VERSION', @id
GO
CREATE PROCEDURE cicd.CheckVersion
@id UNIQUEIDENTIFIER
AS
DECLARE @current NVARCHAR(128)
DECLARE @ret INT
EXEC @ret = cicd.GetProperty'CICD-VERSION', @current OUTPUT
IF(@ret <> 0)
RAISERROR('Not a versioned database', 18, 0)
IF(@current = @id)
RETURN 0
ELSE
RAISERROR('Unknown version', 18, 0)
GO
Una vez que estos procedimientos han sido agregados a mi base de datos puedo marcarla con una “versión inicial” por ejemplo:
EXEC cicd.Set Version '00000000-0000-0000-0000-000000000000'
Siguiendo mi plan, cada vez que requiera hacer un cambio antes de empezar debo primero verificar que la base de datos contiene la versión esperada y después de generar mis cambios debo indicar que la base de datos se encuentra en una nueva versión:
EXEC cicd.CheckVersion '00000000-0000-0000-0000-000000000000'
IF @@ERROR <> 0
SET NOEXEC ON
GO
-- CODE
-- Version AFTER changes
EXEC cicd.SetVersion '11111111-1111-1111-1111-111111111111'
SET NOEXEC OFF
El proceso de reversión es similar, debo primero verificar que estoy revirtiendo la versión hecha por un cambio específico y luego debo regresar mi base de datos a la versión original.
EXEC cicd.CheckVersion '11111111-1111-1111-1111-111111111111'
IF @@ERROR <> 0
SET NOEXEC ON
GO
-- CODE
-- Return to MODEL Version
EXEC cicd.SetVersion '00000000-0000-0000-0000-000000000000'
SET NOEXEC OFF
Esto nos deja con tres archivos:
| Archivo | Propósito |
|---|---|
| apply.sql | Contiene los incrementos o cambios que serán introducidos en esta nueva versión. |
| undo.sql | Contiene las acciones necesarias para reversar de manera segura todos los cambios introducidos en apply.sql. |
| model.sql | Esquema o modelo de base de datos, este archivo contiene los objetos válidos para una versión específica de la base de datos. |
Y el proceso de alto nivel para agregar una nueva versión sería:
- Tomar todos los cambios que existen actualmente en apply y copiarlos a model.
- Actualizar la versión en model con el identificador único que apply establece como la versión después del cambio.
- Generar un nuevo identificador único para representar la próxima versión.
- Actualizar apply para que busque la versión de model antes de aplicar. cambios y establezca la próxima versión con el identificador creado anteriormente.
- Limpiar todos los cambios de apply.
- Actualizar undo para que busque próxima versión antes de intentar deshacer cambios y utilizar la versión que indica model como actual al finalizar el script.
- Limpiar todos los cambios de model.
Probablemente están pensando eso es demasiado trabajo adicional, siete tareas confusas y aun no empiezo a agregar código, es demasiada complejidad adicional… Vamos a tratar de simplificarlo, para ello voy a utilizar un marcador especial arbitrario, por ejemplo --##! y agregaré secciones dentro de apply y undo que indicarán claramente donde debe ir mi código:
--********************
-- BEGIN CHANGES CODE
--********************
--##!
--##!
--********************
-- END CHANGES CODE
--********************
Quizás se estén preguntando: Por qué no incluí a model dentro de los archivos que deben incluir la sección de cambios? Si verifican los pasos, verán que model realmente nunca debe ser editado directamente, sólo se copian los cambios de apply, por lo tanto, sólo debo incluir un marcador simple antes de establecer la versión actual.
--##!
EXEC cicd.SetVersion '00000000-0000-0000-0000-000000000000'
Una vez que mis marcadores están listos puedo simplificar mi esquema escribiendo mis cambios dentro de los marcadores y puedo utilizar una herramienta para que haga todo el proceso de copiado y actualización.
A continuación, revisaremos un ejemplo completo para agregar una tabla de NorthwindTraders a nuestra base de datos. El primer paso es agregar las instrucciones ddl dentro de los marcadores de apply, que en este caso se encuentran vacíos por ser nuestra primera versión:
EXEC cicd.CheckVersion '00000000-0000-0000-0000-000000000000'
IF @@ERROR <> 0
SET NOEXEC ON
GO
--********************
-- BEGIN CHANGES CODE
--********************
--##!
CREATE TABLE [dbo].[Categories]
(
[CategoryID] INT IDENTITY(1,1) NOT NULL,
[CategoryName] NVARCHAR(15) NOT NULL,
[Description] NTEXT NULL,
[Picture] IMAGE NULL,
CONSTRAINT [PK_Categories] PRIMARY KEY CLUSTERED
(
[CategoryID] ASC
)
)
GO
--##!
--********************
-- END CHANGES CODE
--********************
-- Version AFTER changes
EXEC cicd.SetVersion '11111111-1111-1111-1111-111111111111'
SET NOEXEC OFF
Agregamos las sentencias correspondientes en los marcadores de undo que también se encuentran vacíos por la misma razón anterior:
EXEC cicd.CheckVersion '11111111-1111-1111-1111-111111111111'
IF @@ERROR <> 0
SET NOEXEC ON
GO
--********************
-- BEGIN ROLLBACK CODE
--********************
--##!
DROP TABLE [dbo].[Categories]
--##!
--********************
-- END ROLLBACK CODE
--********************
-- Return to MODEL Version
EXEC cicd.SetVersion '00000000-0000-0000-0000-000000000000'
SET NOEXEC OFF
A continuación, agregamos el código a nuestro repositorio de código fuente e iniciamos el proceso de integración, calidad y liberación continua, donde verificaremos en los ambientes de pruebas tanto la aplicación de los cambios como su reversión; si encontramos algún problema los scripts serán corregidos hasta que podamos llevar el cambio de forma segura al ambiente productivo. Una vez que los cambios se propagan hasta el ambiente productivo podemos dar por sentado que “aceptamos” la versión actual.
Es momento de agregar una nueva tabla a nuestra base de datos, deberemos repetir todo el proceso nuevamente, sin embargo, como ya “aceptamos” una nueva versión deberemos utilizar la herramienta de versionamiento para reflejar esto en nuestros scripts.
PS C:\Repos\DB-DevOps> cd scripts
PS C:\Repos\DB-DevOps\scripts> .\DbVersionTool.ps1
Database Versioning Tool
========================
Rollback Version: 00000000-0000-0000-0000-000000000000
Current Version : 11111111-1111-1111-1111-111111111111
PS C:\Repos\DB-DevOps\scripts> .\DbVersionTool.ps1 -update
Database Versioning Tool
========================
Rollback Version: 00000000-0000-0000-0000-000000000000
Current Version : 11111111-1111-1111-1111-111111111111
Next Version : 2aa12efb-4433-41a4-82b2-0c6538cc2810
Updating apply...
Updating model...
Updating undo...
Update Completed!
PS C:\Repos\DB-DevOps\scripts>
Estamos listos para empezar de nuevo, todos los archivos han sido actualizados y las secciones de código han sido procesadas para recibir los nuevos cambios correspondientes a la nueva tabla que será agregada.
Obviamente estamos agregando una sola tabla por simplicidad en el ejemplo, en realidad podemos agregar todos los cambios que sean necesarios, tomando en cuenta que undo debe contener todo lo necesario para revertir todos los cambios introducidos en apply; esto puede incluir eliminar objetos, recrear objetos eliminados, restaurar estructuras de tablas existentes, reacondicionar datos, etc.; un caso particular es la eliminación de datos en apply donde undo podría recrear la tabla pero no restaurar los datos, esa es una tarea que debería planearse de forma manual y extraordinaria con la ayuda de copias de seguridad.
Si desean experimentar con esta estrategia pueden acceder al código de ejemplo para SQL Server en el siguiente repositorio: https://github.com/eulesv/DB-DevOps
Si los marcadores son válidos en el motor de tu elección es posible utilizar la misma herramienta de versionamiento proporcionada para que puedas ajustar los scripts a tus necesidades.
Hasta la próxima!
Este contenido es parte de la serie DevOps y Bases de Datos, si estás interesado en este tema asegúrate de leer toda la serie.